INTRODUCTION TO DATA INFRASTRUCTURE & ANALYTICS
The data market is enormous. Global big data is expected to reach $275B this year thanks to a rapid shift favoring cloud-based storage (like what S3, Snowflake, and Databricks offer). As data is and continues to be a major differentiating factor for companies, more businesses are investing in advanced analytics and data engineering initiatives.
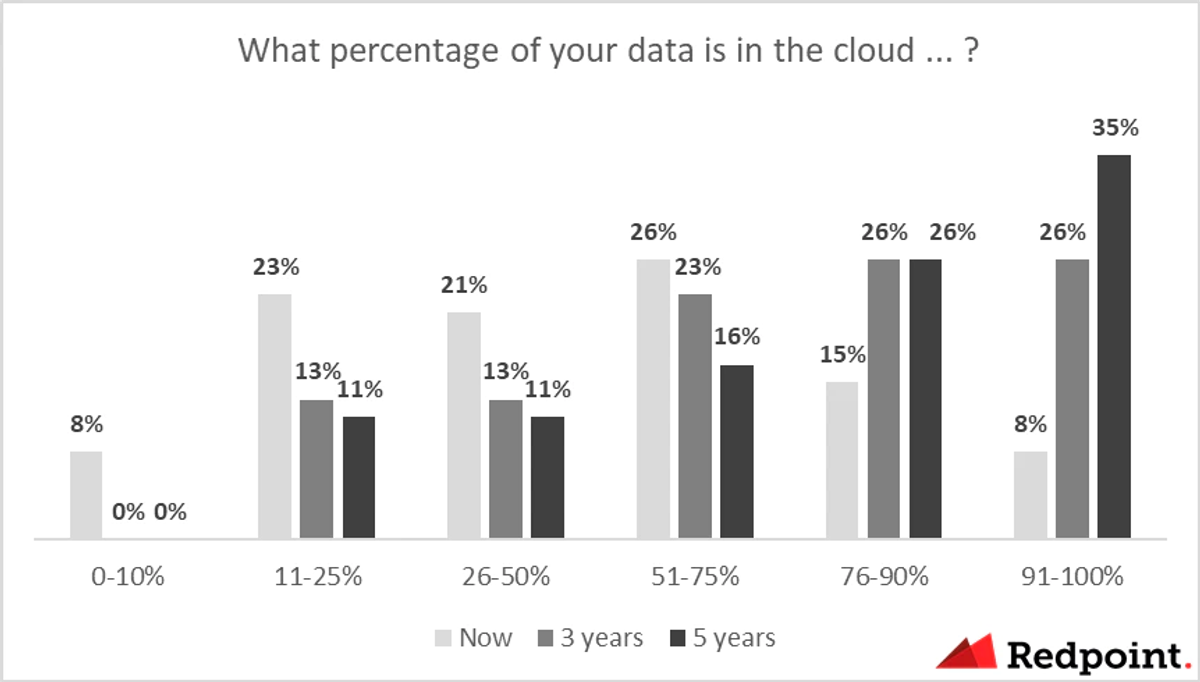
From SMBs to Fortune 500 enterprises, data is embedded within internal workflows and products, resulting in more efficient decision making and other processes. Relying on new data infrastructure tooling to support their own offerings, cloud-based solutions offer critical go-arounds to technical barriers, particularly in managing and assessing such large quantities of data.
Data engineers and analysts continue to grow in demand: In 2021, data engineering job postings ranked in the top YoY growth factor in tech. In third place – data scientists.

Four Key Data Trends
1) Empowering data scientists. As data systems and storage improve, data scientists are equipped to drive analyses and derive powerful insights from underlying data. Startups like Anyscale and Coiled empower data scientists to oversee large-scale experiments and create complex models with ease.
2) Unraveling the data stack. Open ecosystems develop around cloud data, now with a level of interoperability that simply didn’t exist a decade ago. Storage businesses continue to innovate around new data use cases “higher in the stack,” allowing vendors within dashboarding, ETL, data observability, real-time, and more, to flourish. As modular approaches are adopted by teams, hyper-optimized solutions are created to increase the flow of data.

3) Batch → streaming. While batch processing constitutes the majority of data workloads to date, we can also observe a noticeable, growing proportion of net-new analytical workloads moving to real-time and streaming. Real-time and streaming data use cases are seemingly infinite, and continue to change the landscape of current business offerings and future possibilities.
4) Emergence of the Lakehouse. In the midst of their competition, the lakehouse emerged as a by-product between Snowflake and Databricks, combining the best elements of data lakes and data warehouses. In its quest to be the central storage layer for data, Snowflake will support unstructured data formats, whereas Databricks is bringing warehousing capabilities to its data lake. The end result: increased flexibility for data practitioners.
Introduction to Machine Learning
The machine learning (ML) ecosystem is reaching an inflection point. Advancements in this segment are creating unprecedented value felt by every industry. As improvements in natural language processing (NLP) and computer vision (CV) continue, they are redefining how we think about data. From recommendation engines, embedded search, and fraud detection, to chatbots and cybersecurity, machine learning is crucial for software applications across the board. Spend for ML tools is only ramping up in today’s world, with the Enterprise AI market expected to reach $50B+ in spend by 2027.
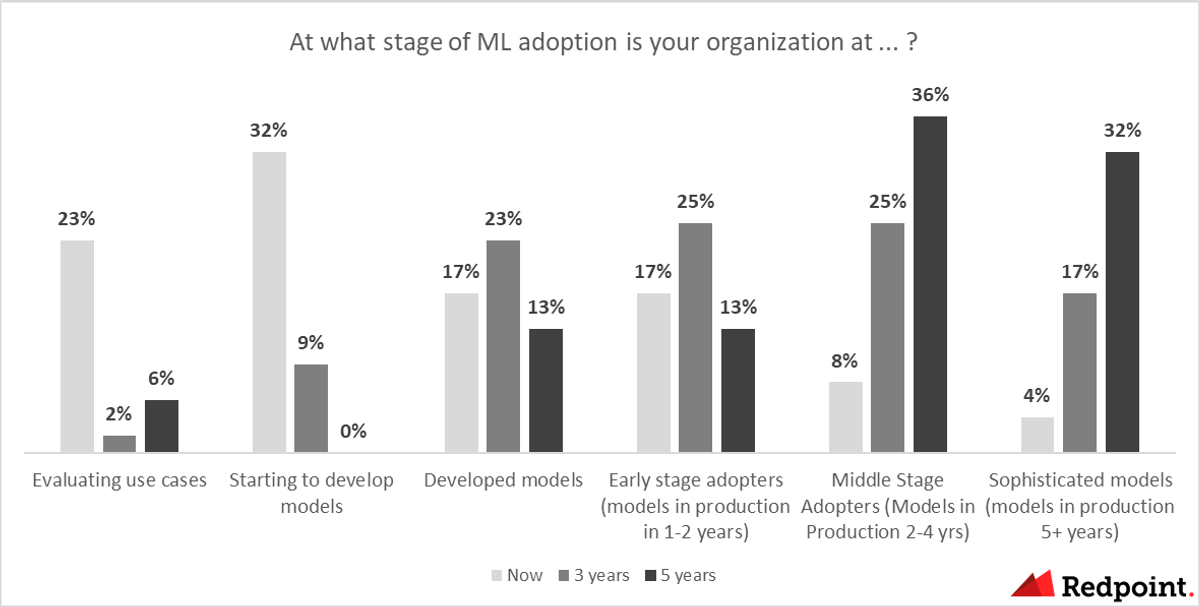
Research labs like Microsoft, Google, and Amazon continue to contribute to the machine learning ecosystem, setting the stage for recent progress. Last year, OpenAI introduced the powerful GPT-3 language model. Because it is open-sourced, it is universally available to developers. These language models are key to creating and scaling machine learning embedded applications.
Four Key Trends in Machine Learning
- The data playbook is setting the tone for ML. Though not as mature as the data market, similar solutions in the machine learning ecosystem around pre-processing, data quality, scalability, observability, real-time, etc., are emerging. Interoperability within the new machine learning stack is not as developed either, and the solutions remain challenging. However, we fully expect machine learning solutions to follow in data’s footsteps. Below are a few ML vendors pushing the envelope in the field.
2) Overlap between software development + machine learning. Machine learning engineers are in high demand. Software engineers can become capable machine learning engineers fairly quickly (given MOOCs and online learning).
3) Deep Learning Use Cases Adoption. Deep Learning is a subset of machine learning modeled after neural networks that mimic the human brain. This subset “learns” large amounts of data and, historically, has been confined to research labs with limited enterprise adoption. The limiting factors include a lack of structured labeled data, appropriate modeling frameworks, and adequate compute resources. Despite these historic challenges, startups like Lambda Labs are beginning to enable enterprises to use cases around deep learning.
4) Specific budgets for ML. Larger enterprises are carving out machine-learning specific budgets, separate from data ones. More frequently, larger companies have a “Head of Machine Learning,” followed by a dedicated junior team and separate budget allocations for ML solutions.
Budgeting for Data and Machine Learning
It should come as no surprise that data budgets have increased alongside evolving demands for data itself. After surveying 60 data leaders in our network within organizations of 500+ FTEs, we learned that nearly 50% of these enterprises possess a data-specific budget greater than $1M, with some leaders managing data budgets upwards of $10M. As data budgets are projected to expand, we expect roughly a quarter of enterprises to double their data spending within the next ten years.
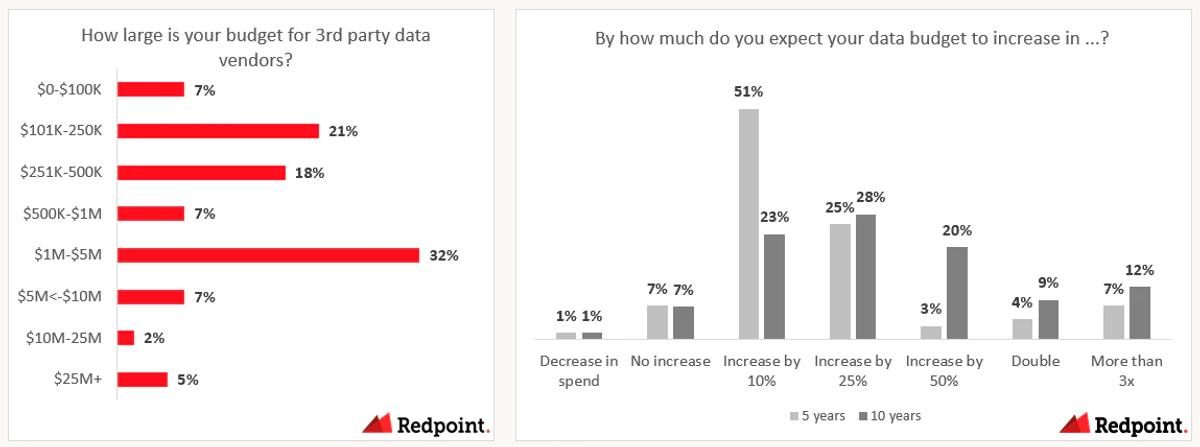
When assessing data spending categories, a quantitative approach helped us understand priorities relative to one another. After giving an imaginary $2M data spending budget to data leaders, they were then asked to rank data solutions by total amount spent. Data leaders were asked to budget hypothetically, with numbers that reflect current spending priorities. Then, these leaders were asked to envision how they might spend in five to ten years. While incomplete in some ways – for example, in providing these subcategories, we cannot account for the emergence of a potential new disruptor – these responses offer valuable insights concerning spending and data prospects.
In reading the tables below, note that teams will likely use multiple vendors, as each provides critical elements within a broader data strategy. Some categories are, by nature, weighted in value, and because of this, spend is not distributed evenly across categories.
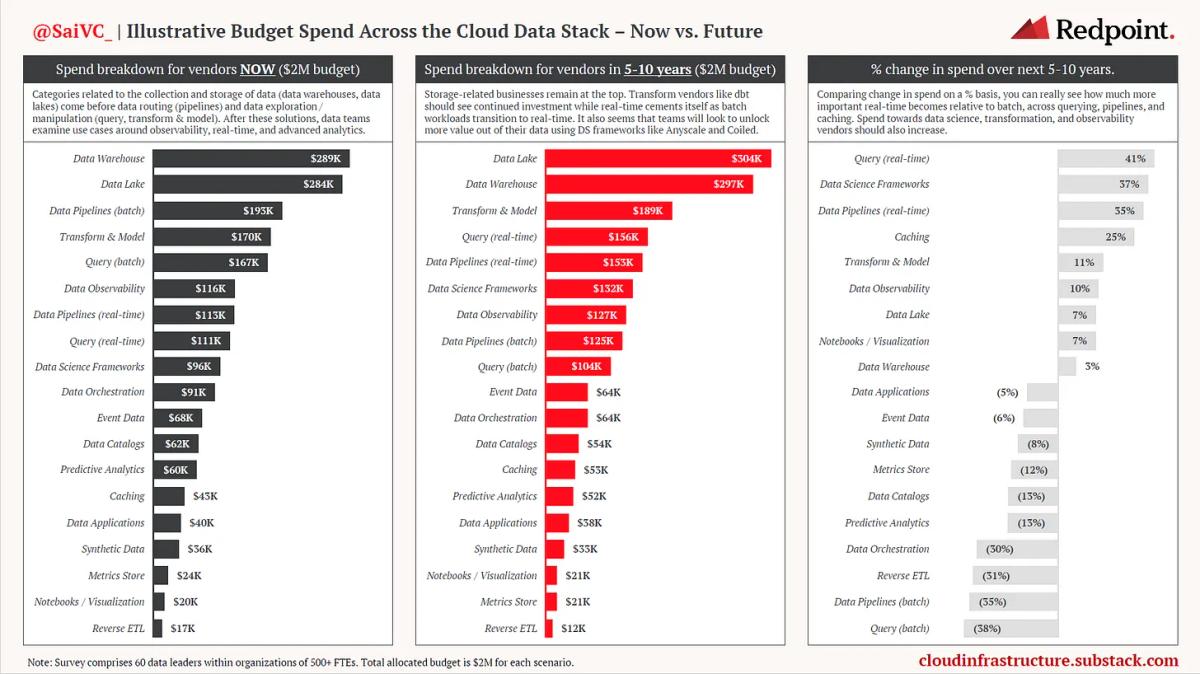
Data teams tend to follow Monica Rogati’s “Data Hierarchy of Needs.” Categories related to the collection and storage of data, like data warehouses and lakes, often come before data routing and the exploration of data). Observability, real-time, and advanced analytics are prioritized after these solutions.
While data budgets remain much larger than machine learning, machine learning ranks as the fastest growing budget within cloud infrastructure. We surveyed 60 ML leaders in our network within organizations of 500+ FTEs and learned that over half expect to double their machine learning budget in the next 5 years. About a quarter further expect to triple their ML budget in the same time period.
Below is the same survey ranked to related spend that data leaders were asked, except this time, ML leaders and AI practitioners were asked for their insight with a $1M budget.
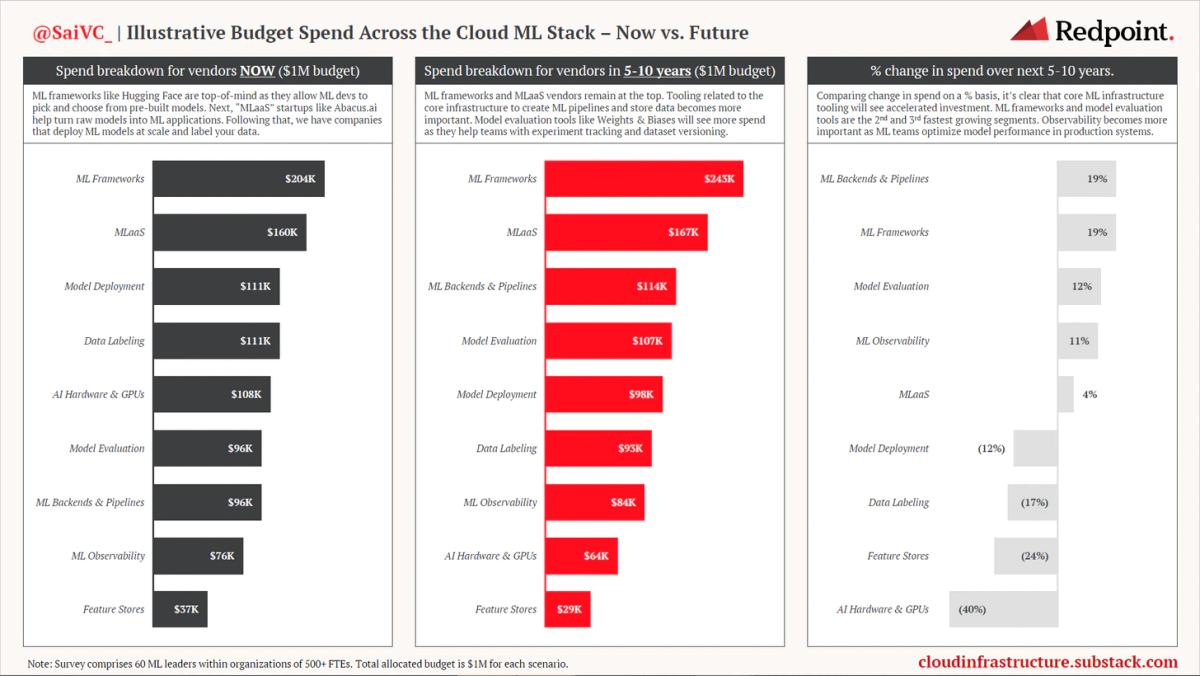
Cohere and Hugging Face are machine learning networks that allow ML developers to pick and choose from pre-built models. Hugging Face has grown to be one of the fastest-growing open source platforms, passing existing repositories managed by Databricks, dbt, and Grafana.
Categories that help turn raw models and data into real-life use cases and machine learning applications (called “MLaaS”) are followed by companies that establish ML models at scale, like OctoML, and those that label training data, like Heartex, Labelbox, and Scale.ai.
THE FUTURE OF DATA AND MACHINE LEARNING
Where is Data Headed?
Storage-related businesses remain at the top, and we’re excited to track the innovation happening within this layer. Companies optimizing the data lake experience, like Onehouse and Tabular, will likely become more important as overall data lake spend increases. Data transformation vendors (such as dbt) should see continued investment.
Real-time related solutions will be one of the fastest growing segments, and in the near future, we can expect real-time querying, streaming pipelines, and database optimization solutions like caching to grow in importance and capability.
Lastly, vendors like Anyscale and Coiled will help companies expand their data science initiatives. We also suspect data observability vendors, like Monte Carlo, will popularize — especially as teams seek to limit data downtime.
As for machine learning, we can expect to see ML frameworks and MLaaS vendors on top. Core ML infrastructures, like workflow orchestrators (Union.ai) and backends (i.e. Pinecone.io which allows for vector embeddings in unstructured ML data) will continue to grow in usage and importance to broader ML function.
Model evaluation tools like Comet and Weights & Biases will be the third fastest growing segment as teams build better models, faster. These developer programs will proceed in helping experiment tracking, dataset versioning, and model management capabilities.
Finally, ML observability vendors such as Arize and Arthur.ai will become more important. These vendors allow companies to measure and optimize model performance in production systems, similar to data observability startups like Bigeye and Monte Carlo.
