Data Update: 2025 InfraRed Report
The slides and discussion below are from the data section of the 2025 InfraRed Report (our take on the current state of cloud infrastructure) as presented at the InfraRed Summit by Sai Senthilkumar and Jordan Segall.
Thanks to the explosion in AI, accomplishing AI workloads requires vast amounts of data across many types of modalities and near real-time performance. In order to accomplish such workloads, there have also been advancements and movement in the data infrastructure space.
We’ll cover 3 major trends that we’ve seen in the past year in the data space, the first two of which are on the infrastructure side which have helped enable said AI workloads:
#1: Apache Iceberg winning the data table format space, which has resulted in what we call a war of data catalogs occurring between Snowflake and Databricks.
#2: The rise of S3 oriented architectures amongst a host of providers to produce benefits such as significantly decreased costs.
#3: The applied side of data & the next evolution of BI and analytics (which is, of course, AI driven analytics).

The first trend is that data lakehouses have become more commonplace, and as companies look to modernize these platforms, they have increasingly turned to Apache Iceberg as the dominant open-table format
Iceberg allows for data reliability at massive scale and on rapidly changing datasets.
We saw significant support for Apache Iceberg across nearly every major cloud vendor, such as confluent releasing Tableflow, and AWS’s S3 tables and announcing Iceberg their chosen format.
And we saw this widespread support due to usage across a variety of use cases, such as:
- Real-time streaming (like with LinkedIn)
- Large-scale analytics where Iceberg enabled Adobe to power billions of events per day for user personalization
- Enabling AI workflows, such as for Salesforce to handle frequent schema changes, partition pruning, and other features

The rise of Iceberg has led to an all-out war over compatibility with the format and adoption over the community.
All within weeks of each other, Databricks announced Unity Catalog OS with interoperability across Iceberg, while Snowflake announced their new OS catalog for Iceberg called Polaris.
Things came to a head when the two fought over Tabular, a startup from the creators of Iceberg bought for nearly $2B, stressing the importance of Iceberg to the broader lakehouse war between the two giants.
The war is still far from over, but it’s clear the lakehouse movement has accelerated in the past year with advancements like Iceberg and these catalogs.
And it’s clear that AI is a large part of that as AI workloads require large-scale, resilient, and efficient data pipelines - the types that Iceberg will enable across areas like distributed training, inference, and dataset versioning.

Due to the increase in the amount of data being processed in AI pipelines and the size of embeddings that must be stored, more efficient architectures are required to enable AI-related features at reasonable prices.
Traditional solutions stored data on local SSDs as the source of truth storage layer to read and write data to local disks.
Today we’re seeing more companies use S3 or blob storage as their persistence layer. While there are some drawbacks such as from a latency perspective, there are a huge host of benefits such as significantly reduced cost, much less operational complexity and autoscaling, and increased reliability.
It is easy to see why AI-based startups are turning toward such architectures - for example, Cursor switched to Turbopuffer to store 100B+ vectors and save 20x costs as a result of this architecture.
Next-gen storage solutions like Warpstream, Neon, and Turbopuffer have adopted such an architecture, and we anticipate this to be a new standard for many future db providers optimizing for certain parameters like cost and ease of use.
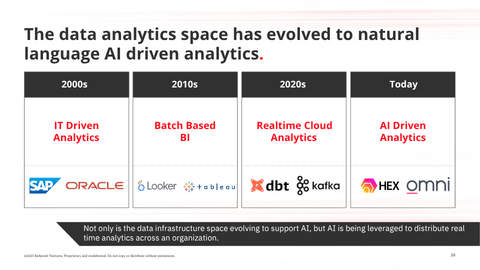
Finally, not only is the data infrastructure space evolving to support AI, but AI is being leveraged from an applied data perspective to distribute real-time analytics across an organization
If we explore the evolution of data analytics and go back to the 2000s:
- The 2000s primarily revolved around Centralized IT driven reporting for executives with solutions like SAP, Oracle, etc.
- Fast forward to the 2010s and we see Datalakes (Snowflake, Redshift) + data processing tools (Spark, Hadoop) enable user facing self serve BI (Tableau, Power BI, Looker).
- Then in the late 2010s and early 2020s, we get to cloud-native analytics - realtime and scalable analytics as a result of cloud data warehouses and modern data stack with new technology like Kafka, dbt, and Monte Carlo.
Finally today, we’ve seen the next evolution of data analytics with AI-driven analytics with tools like Omni and Hex, where all users interact with company-wide data via an AI chat interface, accessible to any user and truly dynamic and personalized to their needs.
It’s clear that data infrastructure will continue to adapt to support the growing needs of AI, especially as multimodality use cases continue to proliferate and the usage of AI continues to rise at an increasing rate, and we’re excited to see what advancements are developed in the next year.
Read the full InfraRed Report here.